- Pierre Clayton's Newsletter
- Posts
- 📓 Notebook of the Week: Kimi-VL is the Vision-Language beast YOU can run
📓 Notebook of the Week: Kimi-VL is the Vision-Language beast YOU can run
Pierre Clayton
April 20, 2025
Welcome to our very first Notebook of the Week! 🎉
Today, we're diving into a multimodal model that actually runs on your hardware—Kimi-VL.
This open-source gem from Moonshot AI cleverly balances massive capabilities with real-world efficiency, and the technical report arXiv:2504.07491 is packed with goodness. But we didn’t stop at reading it—we ran the code, peeked under the hood, and watched the model reason step by step through images and complex prompts.
Let’s break it down. 🔍
🔍 The Problem
Vision-Language Models (VLMs) are amazing—but they’re often too heavy to run locally, too dense to scale, or too limited in their reasoning. Many struggle with high-resolution images, long contexts, or multi-turn multimodal tasks.
And when they do excel, they're often locked behind APIs or expensive proprietary walls. So how do we build a powerful, open, and efficient VLM that can run on accessible hardware and still compete with the GPT-4os of the world?
📚 How They Studied It
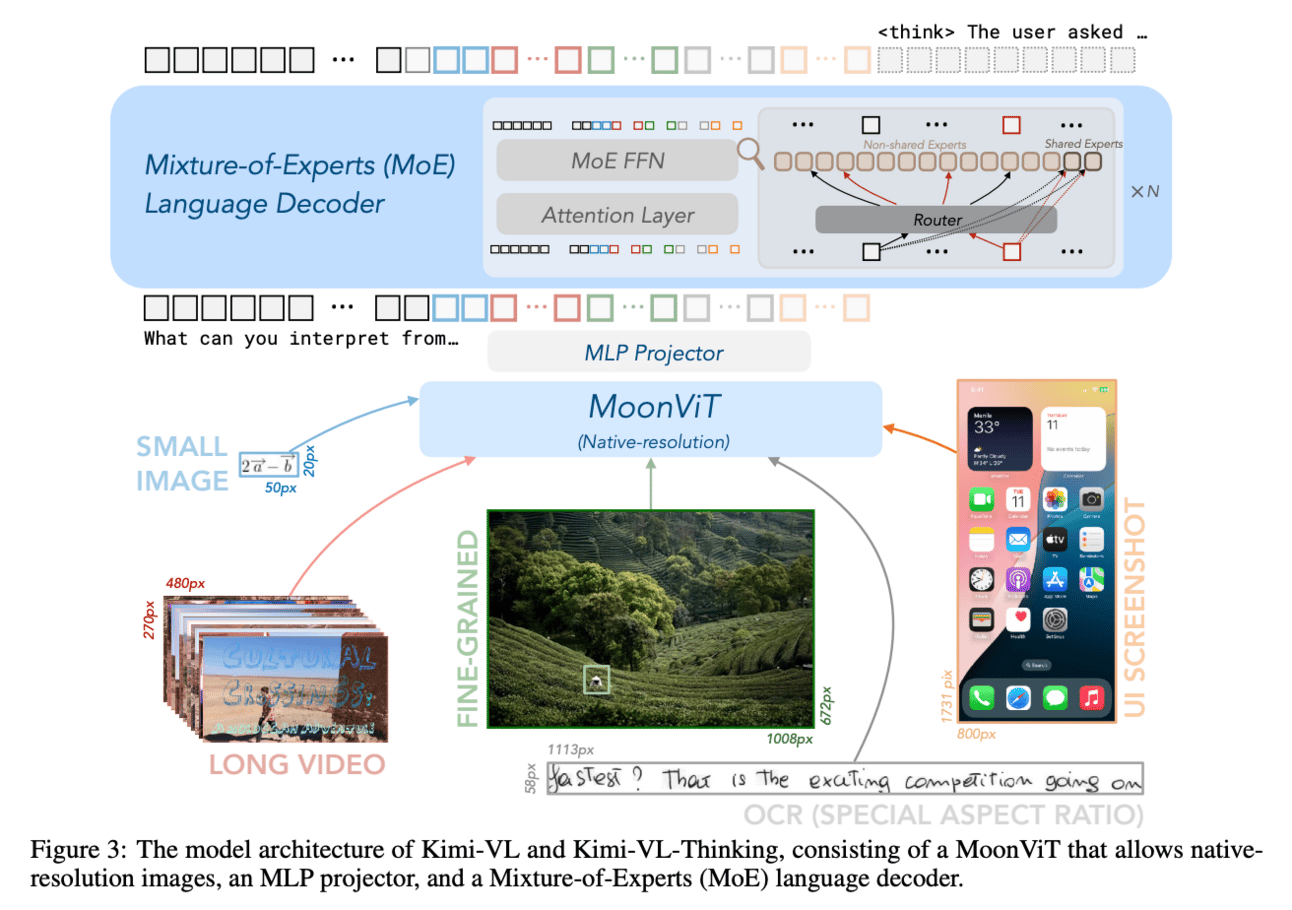
The team behind Kimi-VL tackled this challenge with an architecture that brings together three stars:
MoonViT for vision (supports native resolution!),
a clever MLP projector to bridge vision and language,
and Moonlight, a Mixture-of-Experts (MoE) language model that only activates ~2.8B params per token (from a 16B pool 😮).
They trained this architecture in multi-stage passes—starting with component-level pretraining, then full-model fine-tuning, then Chain-of-Thought + RL to craft the Thinking variant.
👉 Here’s a glimpse of their process:
📈 What They Found
Kimi-VL is no lightweight when it comes to results. Here's how it performs:
🚨💻 Go check out the Google Colab notebook to run these examples yourself (download and open it in your environment) and dive deeper into the architecture! 💻🚨


Both models handle long documents, high-res screenshots, and multi-image inference, with Thinking shining especially bright on math and logic problems.
🧠 Why It Matters in Real Life
✅ You can actually run these models on Colab Pro (if you're careful with VRAM).
🧠 The Thinking variant really does think—great for math, science, and agent tasks.
👁️ The native-resolution vision encoder handles tiny text and UI elements like a champ.
🧪 Instruction tuning makes it useful out of the box for OCR, reasoning, and multi-image Q&A.
🔧 Integration with Hugging Face, LLaMA-Factory, and vLLM makes it super dev-friendly.
It’s not just a cool paper—it’s a legit tool you can use today.
🚀 The Big Picture
Kimi-VL proves we don’t need to choose between power and practicality.
Thanks to MoE efficiency, native vision fidelity, and structured training, it offers a glimpse at the future of multimodal agents:
capable of deep reasoning, equipped with memory, and deployable by you.
It's smarter, cheaper, and more open than you think. And best of all?
It's just getting started.
Access the notebook here:
